Matrix Multiplication Cuda Github
The number of lines of Matrix B. Void mm matrix a matrix b matrix result int i j k.
Underfox On Twitter For The First Time Researchers Have Developed A New Gpu Based Framework To Perform Sparse General Matrix Matrix Multiplication Using Nvidia Tensor Cores Https T Co Tdlqkumjwv Https T Co Whr5jem1bj
X block_size_x threadIdx.
Matrix multiplication cuda github. I for j 0. Element ij a. For int k 0.
Since the multiplications and additions can actually be fused into a. We use the example of Matrix Multiplication to introduce the basics of GPU computing in the CUDA environment. Cuda-Matrix-Multiplication Matrix Multiplication on GPGPU in CUDA is an analytical project in which we compute the multiplication of higher order matrices.
For i 0. Pvalue Aelement Belement. To do the MNK multiplications and additions we need MNK2 loads and MN stores.
Float sum 00. It is assumed that the student is familiar with C programming but no other background is assumed. C ty MATRIX_SIZEs tx Pvalue.
The number of lines of Matrix A. Insert code to implement matrix multiplication here. The main reason the naive implementation doesnt perform so well is because we are accessing the GPUs off-chip memory way too much.
Please count with me. Y tx threadIdx. This sample implements matrix multiplication as described in Chapter 3 of the programming guide.
In this project I applied GPU Computing and the parallel programming model CUDA to solve the diffusion equation. K WIDTH. One of the oldest and most used matrix multiplication implementation GEMM is found in the BLAS library.
Element ik b. X ty threadIdx. One platform for doing so is NVIDIAs Compute Uni ed Device Architecture or CUDA.
MultShareh Author- Robert Hochberg January 24 2012 Author note. The number of columns of Matrix A. K sum.
Int bx blockIdx. Float Belement b k MATRIX_SIZEs tx. J for k 0.
Y block_size_y threadIdx. The number of columns of Matrix B. Matrix Multiplication using GPU CUDA Cuda Matrix Implementation using Global and Shared memory.
If nothing happens download Xcode and try again. Matrix multiplication is an essential building block for numerous numerical algorithms for this reason most numerical libraries implements matrix multiplication. Tiling in the local memory.
Thread block size define BLOCK_SIZE 16 __global__ void MatMulKernel const Matrix const Matrix Matrix. The code for this tutorial is on GitHub. Float Aelement a ty MATRIX_SIZEs k.
The input follows this pattern. This project is a part of my thesis focusing on researching and applying the general-purpose graphics processing unit GPGPU in high performance computing. Matrix multiplication.
Do the multiplication. Note that the evaluation of C should be put in the conditional loop to guarentee. The values of Matrix A.
Matrix Multiplication for CUDA explanation. X by blockIdx. Element kj Each kernel computes the result element ij.
Y Row by TILE_WIDTH ty Col bx TILE_WIDTH tx. We performed the operations on both CPU and different GPUs and compare their results based on the time required for calculations and also calculated their CPU to GPU ratio. When batch size is equal to 1 it becomes a regular matrix multiplication.
It has been written for clarity of exposition to illustrate various CUDA programming principles not with the goal of providing the most performant generic kernel for matrix multiplication. Based nearly entirely on the code from the CUDA C Programming Guide include Matrices are stored in row-major order. A torchrandnbatch_size M K b torchrandnbatch_size K N c torchbmma b c has shape batch_size M N Here is the source code of my BMM kernel.
Parallel-computing cuda gpgpu matrix-multiplication high-performance. Instantly share code notes and snippets. In this video we look at writing a simple matrix multiplication kernel from scratch in CUDAFor code samples.
Writefile matmul_naivecu define WIDTH 4096 __global__ void matmul_kernel float C float A float B int x blockIdx. Matrix Multiplication on GPU using Shared Memory considering Coalescing and Bank Conflicts - kberkayCuda-Matrix-Multiplication. Here is an example code in pytorch.
C A B. If nothing happens download GitHub Desktop and try again. The values of Matrix B.
Mrow col Melements row Mwidth col typedef struct int width. __global__ void mm_kernel matrix a matrix b matrix result int size. Int y blockIdx.
Execute the following cell to write our naive matrix multiplication kernel to a file name matmul_naivecu by pressing shiftenter.
Github Kky Fury Cuda Matrix Multiplication

Pin On Useful Links

Cs Tech Era Tiled Matrix Multiplication Using Shared Memory In Cuda
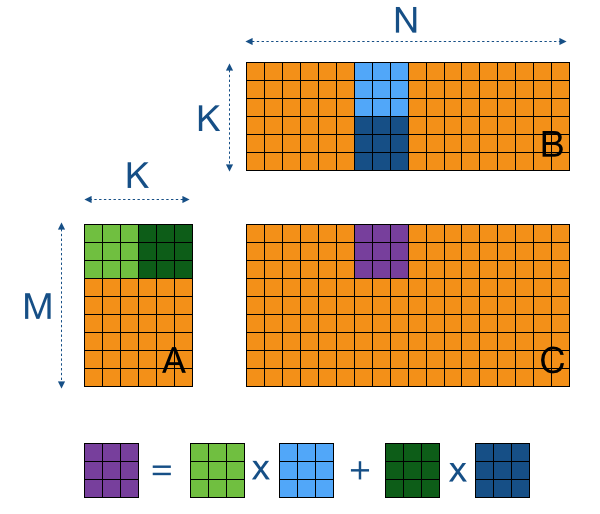
Opencl Matrix Multiplication Sgemm Tutorial
Github Maxkotlan Cuda Matrix Multiplication Benchmark A Quick Benchmark Comparing The Difference Between Cpu Matrix Multiplication And Gpu Matrix Multiplication

The Structure Of A Matrix Multiplication Operation Using The Blis Download Scientific Diagram
Tiled Matrix Multiplication

General Matrix To Matrix Multiplication Between The Current Hsi Data Download Scientific Diagram
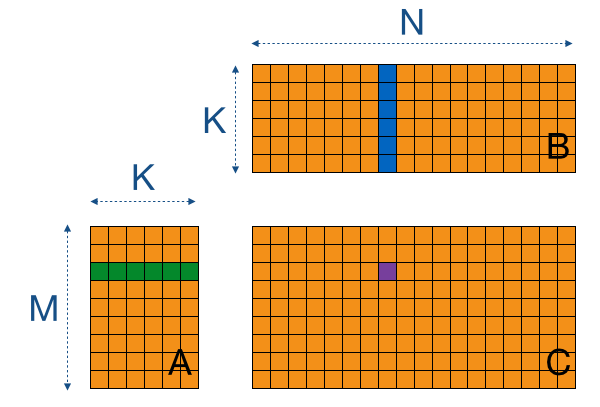
Opencl Matrix Multiplication Sgemm Tutorial

Pin On Useful Links
Github Cvryn7 Matrix Multiplication With Tiling Cuda Matrix Multiplication Using Cuda C

Generating Families Of Practical Fast Matrix Multiplication Algorithms
Github Gsheni Matrixmultiplication A Matrix Multiplication Implementation In C And Cuda
Github Kberkay Cuda Matrix Multiplication Matrix Multiplication On Gpu Using Shared Memory Considering Coalescing And Bank Conflicts
Introduction To Cuda Lab 03 Gpucomputing Sheffield

Github Rushirg Cuda Matrix Multiplication Matrix Multiplication On Gpgpu In Cuda

Pin On Useful Links
Github Alepmaros Cuda Matrix Multiplication Matrix Multiplication Using Cuda

Matrix Multiplication Cuda Eca Gpu 2018 2019